
量子位新品速递|第7期:复旦触觉具身获近亿融资、DeepSeek自动研究论文出炉、北大3D编辑提速120倍
本期收录3款量子位5月27日报道的科技新品:新智具身智能完成近亿元天使轮融资,三位出自微软/阿里/华为的科学家打造触觉具身智能;DeepSeek研究员陈德里用自研DeliAutoResearch自动Agent,2小时思考产出45页论文;北大&港中文&上海AI Lab联合推出VGGT-Edit,5秒完成3D场景编辑,较传统方法提速120倍。
研究速览
本期收录 3 款量子位 5 月 27 日报道的科技新品:复旦系触觉具身公司新智具身获近亿元天使轮,微软/阿里/华为背景团队入局;DeepSeek 研究员用 AI Agent 自动写论文,45 页只需 2 小时脑力;北大等机构发布 VGGT-Edit,5 秒改 3D 场景实现 120 倍加速。
新智具身智能:触觉具身梦之队天使轮近亿,微软/阿里/华为老兵入局
5 月 27 日,上海新智具身智能科技有限公司(NeoteAI)宣布完成近亿元天使轮融资,由上海国投旗下上海科创集团与复旦科创联合领投。公司源自复旦大学可信具身智能研究院,定位触觉具身智能赛道——解决传统机器人视觉看懂了、却"摸不懂"的精细操作难题。1
核心团队堪称"梦之队": CEO 赵世豪本硕复旦、港大博士,曾任职微软全球研究院和阿里通义实验室;首席科学家吴祖煊为复旦可信具身智能研究院副院长,曾任职 Meta;COO 董道国曾任华为荣耀 Magic 一代首席架构师,拥有近 20 年产业经验。1
三大技术板块同步推进:

- 自研视触觉传感器:内置微型光学相机,拍摄柔性硅胶接触形变,端侧深度学习解耦出六维力、滑移轨迹、物体轮廓等物理信息,数据格式与视觉 Transformer 天然兼容
- 触觉具身数据采集中心:超千平方米规模,真机采集线与便携式采集终端互补,数据优先供给内部模型训练
- 触觉具身大模型:VTLA 模型可实时感知夹持、滑移等接触真实状态,解决传统 VLA 感知盲区导致的精细操作失败
有趣的是,新智具身承接了复旦与上海的战略合作,初创期已获得静安区及上海市经信委、市科委的多级政策与资金支持,叠加复旦研究院的多团队产出,算是典型的"产学研地方协同"标杆项目。1
DeepSeek DeliAutoResearch:AI 自动写 45 页论文,人类思考仅 2 小时
DeepSeek 资深研究员陈德里(Deli Chen)发布了一项实验性成果——他自建的 DeliAutoResearch 自动研究 Agent,以 DeepSeek-V4-Pro 负责文字、GPT-Image2 负责插图,AI 贡献了论文 99%的内容,仅用 2 小时人类思考便完成了一篇 45 页的学术综述。2
创作数据: 论文共迭代 6 次,初稿仅 76 分钟,总耗时 6 天;Agent 运行约 108 轮,消耗 64.8 万 token,写出 2234 行 LaTeX 代码;103 篇参考文献全部核验。陈德里本人感叹:"同样的工作以前至少需要一个月,这次碳基大脑的'总 CPU 时间'不到 2 小时。"2
论文核心输出四项成果:

- L1-L5 自主能力分级体系——从 L1 自动补全到 L5 完全自主定向研究,类比自动驾驶 SAE 等级,为混乱的 Agent 领域建了一个清晰谱系
- 四大架构模式分析——单智能体循环、多智能体协作、分层编排、工具增强执行,逐一评估可扩展性、成本、可靠性与监管参数
- 17 款主流系统评测——基于六维特征矩阵分析,发现当前前沿系统普遍处于 L4 级别,L5 仍停留在构想阶段
- 六大待解难题——认知死循环、上下文窗口限制、创新价值评估、结果可复现性、安全风险、使用成本
其中核心判断是:实现 L5 的核心瓶颈不再是模型基础性能,而是长效知识沉淀、可靠的自我评估能力,以及具备理论支撑的架构规模化方案。2
VGGT-Edit:北大等发布原生 3D 编辑框架,5 秒改场景、120 倍加速
北京大学、香港中文大学、上海 AI Lab、NTU 等机构联合提出 VGGT-Edit,一个直接在 3D 空间完成编辑的框架——输入一句"把椅子移到窗边",5 秒内即可完成,且多视角一致、背景不变形,最高较传统方法加速 120 倍。3
它解决了什么核心问题?
现有 3D 编辑绕不开 2D——把场景拆成多张 2D 图片,逐张编辑,再重新拼回 3D。每张图独立处理导致一个视角删了椅子、换个角度椅子又出现,且速度极慢。VGGT-Edit 彻底放弃"2D 搬运"思路,在原生 3D 几何结构上操作。
三大技术创新:
- 残差场预测:不重新生成整个场景,只预测局部变化的残差(新场景=原场景+局部变化),背景毫发不动
- 深度同步文本注入:在解码器多个关键层持续注入文本嵌入,让模型始终感知"要改什么、改哪里"
- 视角感知加权模块:自动评估不同视角可靠性,过滤无效信息
效果数据(DeltaScene 测试集):
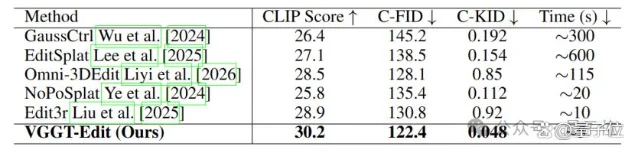
| 指标 | VGGT-Edit | 最佳竞品(Edit3r) |
|---|---|---|
| CLIP Score↑(语义一致性) | 30.2 | 28.9 |
| C-FID↓(分布距离) | 122.4 | 130.8 |
| C-KID↓(核距离) | 0.048 | 0.92 |
| 单次编辑时间↓ | ~5 秒 | ~10 秒 |
对比最慢的方案(GaussCtrl 约 300 秒),VGGT-Edit 实现最高 120 倍加速。论文预印本已在 arXiv 发布(2605.15186)。3
本期三款产品路径各异但指向同一个方向:AI 正在从"看懂世界"进化到"动手改造世界"。触觉传感器让机器人精细化操作有了物理感知,自动研究 Agent 让 AI 可以独立完成科研产出,3D 编辑框架让 AI 能在 3D 空间中直接修改场景——感知、推理、行动三层能力都在加速补齐。
围绕这条内容继续补充观点或上下文。